
Documentation for version v1.9 is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date documentation, see the latest version.
How Velero Works
Each Velero operation – on-demand backup, scheduled backup, restore – is a custom resource, defined with a Kubernetes Custom Resource Definition (CRD) and stored in etcd. Velero also includes controllers that process the custom resources to perform backups, restores, and all related operations.
You can back up or restore all objects in your cluster, or you can filter objects by type, namespace, and/or label.
Velero is ideal for the disaster recovery use case, as well as for snapshotting your application state, prior to performing system operations on your cluster, like upgrades.
On-demand backups
The backup operation:
-
Uploads a tarball of copied Kubernetes objects into cloud object storage.
-
Calls the cloud provider API to make disk snapshots of persistent volumes, if specified.
You can optionally specify backup hooks to be executed during the backup. For example, you might need to tell a database to flush its in-memory buffers to disk before taking a snapshot. More about backup hooks.
Note that cluster backups are not strictly atomic. If Kubernetes objects are being created or edited at the time of backup, they might not be included in the backup. The odds of capturing inconsistent information are low, but it is possible.
Scheduled backups
The schedule operation allows you to back up your data at recurring intervals. You can create a scheduled backup at any time, and the first backup is then performed at the schedule’s specified interval. These intervals are specified by a Cron expression.
Velero saves backups created from a schedule with the name <SCHEDULE NAME>-<TIMESTAMP>, where <TIMESTAMP> is formatted as YYYYMMDDhhmmss. For more information see the
Backup Reference documentation.
Backup workflow
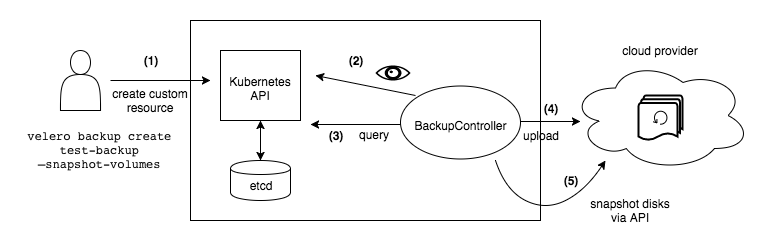
When you run velero backup create test-backup:
-
The Velero client makes a call to the Kubernetes API server to create a
Backupobject. -
The
BackupControllernotices the newBackupobject and performs validation. -
The
BackupControllerbegins the backup process. It collects the data to back up by querying the API server for resources. -
The
BackupControllermakes a call to the object storage service – for example, AWS S3 – to upload the backup file.
By default, velero backup create makes disk snapshots of any persistent volumes. You can adjust the snapshots by specifying additional flags. Run velero backup create --help to see available flags. Snapshots can be disabled with the option --snapshot-volumes=false.
Restores
The restore operation allows you to restore all of the objects and persistent volumes from a previously created backup. You can also restore only a filtered subset of objects and persistent volumes. Velero supports multiple namespace remapping–for example, in a single restore, objects in namespace “abc” can be recreated under namespace “def”, and the objects in namespace “123” under “456”.
The default name of a restore is <BACKUP NAME>-<TIMESTAMP>, where <TIMESTAMP> is formatted as YYYYMMDDhhmmss. You can also specify a custom name. A restored object also includes a label with key velero.io/restore-name and value <RESTORE NAME>.
By default, backup storage locations are created in read-write mode. However, during a restore, you can configure a backup storage location to be in read-only mode, which disables backup creation and deletion for the storage location. This is useful to ensure that no backups are inadvertently created or deleted during a restore scenario.
You can optionally specify restore hooks to be executed during a restore or after resources are restored. For example, you might need to perform a custom database restore operation before the database application containers start.
Restore workflow
When you run velero restore create:
-
The Velero client makes a call to the Kubernetes API server to create a
Restoreobject. -
The
RestoreControllernotices the new Restore object and performs validation. -
The
RestoreControllerfetches the backup information from the object storage service. It then runs some preprocessing on the backed up resources to make sure the resources will work on the new cluster. For example, using the backed-up API versions to verify that the restore resource will work on the target cluster. -
The
RestoreControllerstarts the restore process, restoring each eligible resource one at a time.
By default, Velero performs a non-destructive restore, meaning that it won’t delete any data on the target cluster. If a resource in the backup already exists in the target cluster, Velero will skip that resource. You can configure Velero to use an update policy instead using the
--existing-resource-policy restore flag. When this flag is set to update, Velero will attempt to update an existing resource in the target cluster to match the resource from the backup.
For more details about the Velero restore process, see the Restore Reference page.
Backed-up API versions
Velero backs up resources using the Kubernetes API server’s preferred version for each group/resource. When restoring a resource, this same API group/version must exist in the target cluster in order for the restore to be successful.
For example, if the cluster being backed up has a gizmos resource in the things API group, with group/versions things/v1alpha1, things/v1beta1, and things/v1, and the server’s preferred group/version is things/v1, then all gizmos will be backed up from the things/v1 API endpoint. When backups from this cluster are restored, the target cluster must have the things/v1 endpoint in order for gizmos to be restored. Note that things/v1 does not need to be the preferred version in the target cluster; it just needs to exist.
Set a backup to expire
When you create a backup, you can specify a TTL (time to live) by adding the flag --ttl <DURATION>. If Velero sees that an existing backup resource is expired, it removes:
- The backup resource
- The backup file from cloud object storage
- All PersistentVolume snapshots
- All associated Restores
The TTL flag allows the user to specify the backup retention period with the value specified in hours, minutes and seconds in the form --ttl 24h0m0s. If not specified, a default TTL value of 30 days will be applied.
The effects of expiration are not applied immediately, they are applied when the gc-controller runs its reconciliation loop every hour.
If backup fails to delete, a label velero.io/gc-failure=<Reason> will be added to the backup custom resource.
You can use this label to filter and select backups that failed to delete.
Implemented reasons are:
- BSLNotFound: Backup storage location not found
- BSLCannotGet: Backup storage location cannot be retrieved from the API server for reasons other than not found
- BSLReadOnly: Backup storage location is read-only
Object storage sync
Velero treats object storage as the source of truth. It continuously checks to see that the correct backup resources are always present. If there is a properly formatted backup file in the storage bucket, but no corresponding backup resource in the Kubernetes API, Velero synchronizes the information from object storage to Kubernetes.
This allows restore functionality to work in a cluster migration scenario, where the original backup objects do not exist in the new cluster.
Likewise, if a Completed backup object exists in Kubernetes but not in object storage, it will be deleted from Kubernetes since the backup tarball no longer exists.
Failed or PartiallyFailed backup will not be removed by object storage sync.
Getting Started
To help you get started, see the documentation.